
转载自https://ui.marklion.cn/article/7e7/06/article-2ad6830869c1feee.shtml
ControlNet 1.1在1.0基础上增加模型至14个,采用“版本号+模型状态+Stable Diffusion版本+后缀”命名规则,如control_v11p_sd15_canny,
v11为1.1版,p代表模型状态,模型状态总共有三种,”p、e、u“
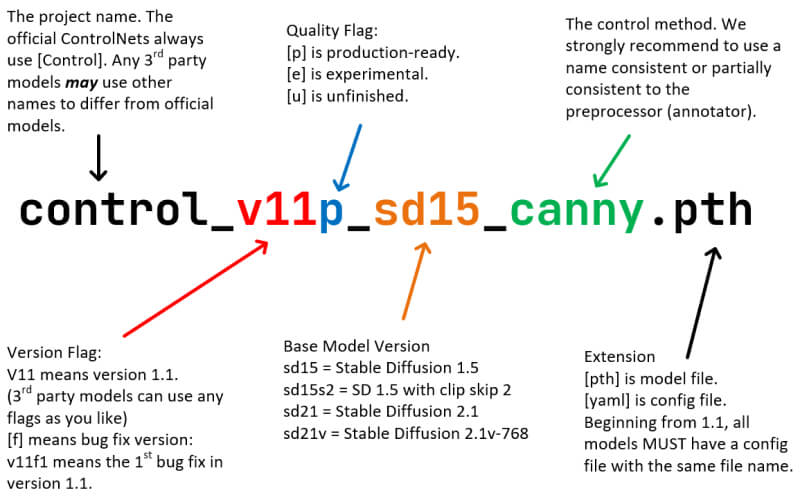
模型状态,p表示正式版(production),e表示实验版本(experimental),u表示未完成(unfinished)。
正式版模型以Control_VxxyP_开头,表示该模型已经比较稳定,适合新手使用。
实验版本模型以Control_VxxyE_开头,表示该模型仍在实验阶段,结果可能不太稳定,更适合研究者探索。
测试结束的模型以Control_Vxxxu_开头,表示模型尚未完成。
模型名称,如SD15表示基于Stable Diffusion 1.5版本的模型。
后缀为.pth,同时从1.1开始所有模型都需要搭配.yaml后缀的配置文件,下载模型时需要两个.pth和.yaml两个文件。
下面将对目前的14个模型做一一介绍:
1. Depth深度图模型
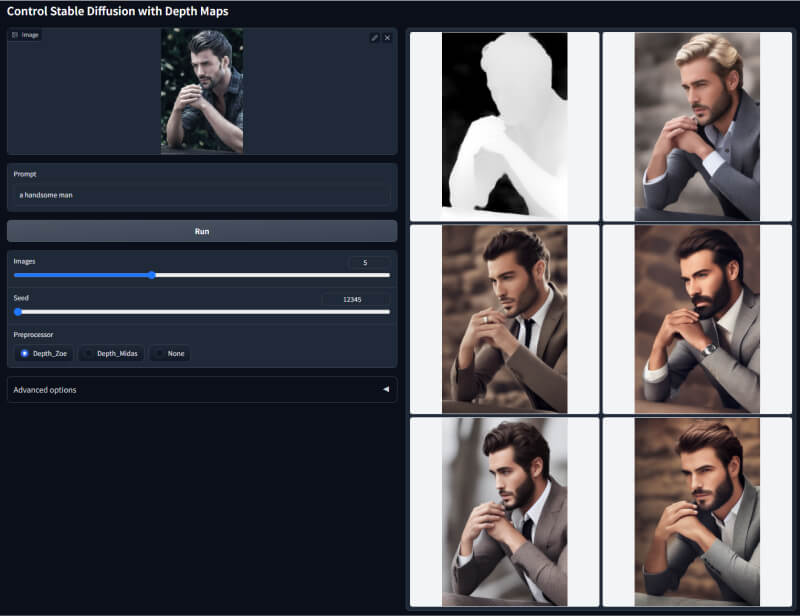
该模型可以分析图像中的深度信息,判断不同物体的空间位置关系,如人物与背景的前后位置、手臂在身前身后的位置等。它利用深度学习技术分析RGB图像中的立体要素,判断像素的深度差异,从而确定物体的空间布局。常用于人物换背景,调整手臂位置等创意设计。
2. Normal法线贴图模型
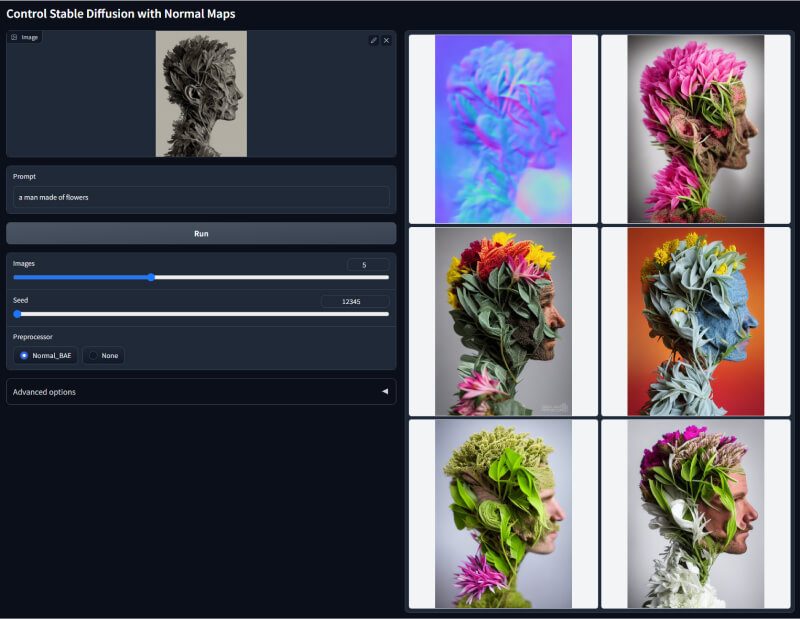
该模型通过检测图像中每个像素的RGB颜色值和表面法线方向,来判断物体的边界和明暗部。它可以分离主体和背景,单独控制亮部和暗部的颜色曲线来重绘图像。常用于增加蓝色通道以表现夜晚或日落的色调,或者用于整体图像色彩方面的调整。
3. Openpose人体姿态检测模型
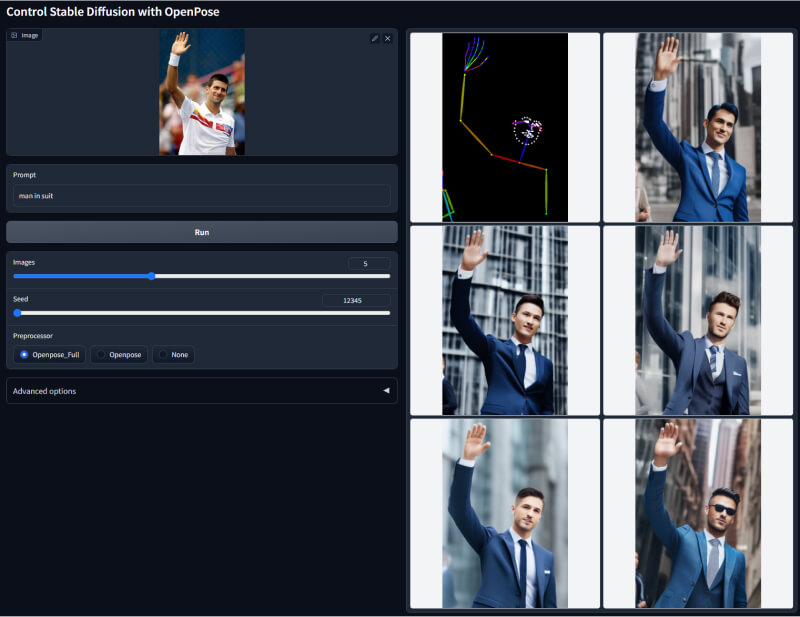
该模型使用深度学习技术检测人体各关键点之间的关节点和运动轨迹,识别人体姿态包括面部和手部运动。它可以处理包含多人的图像,识别每个人物的具体姿态。常用于调整人物手臂位置、生成新表情等创意设计。
4. Segmentation语义分割网络
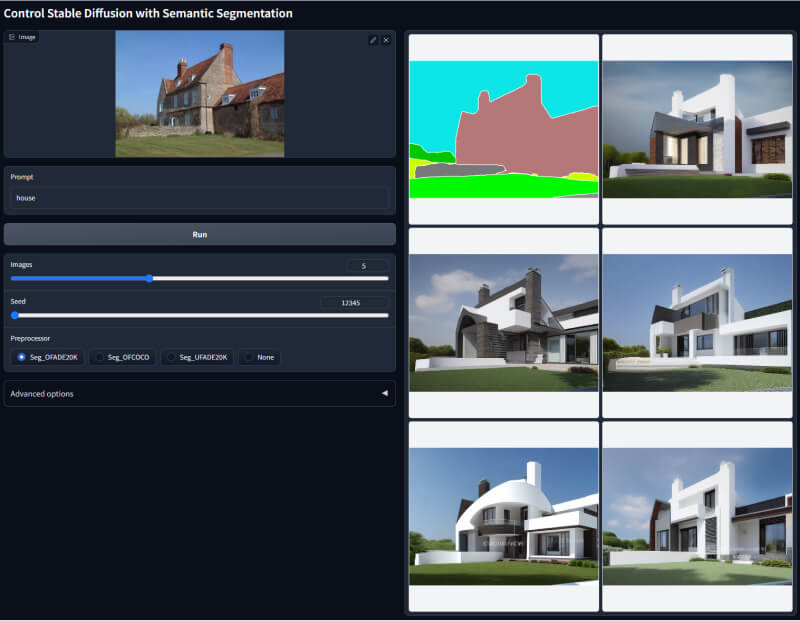
该模型使用深度学习技术,根据图像中物体的视觉特征将其分割为约150种颜色,每个颜色代表一个分类的物体。它可以识别图像中各种要素如天空、建筑、树木等,并单独对每个要素进行处理。常用于单独更改天空颜色或识别树木并修改等。
5. Shuffle随机处理模型

该模型可以随机打乱图像的各个要素,包括颜色、形状、构图等,并重新随机组合生成全新的图像。该模型可以提取源图像和参考图像的内容特征和风格特征,将参考图像的风格特征迁移到源图像的内容特征上,生成风格化后的输出图像。
6. IP2P直接编辑模型
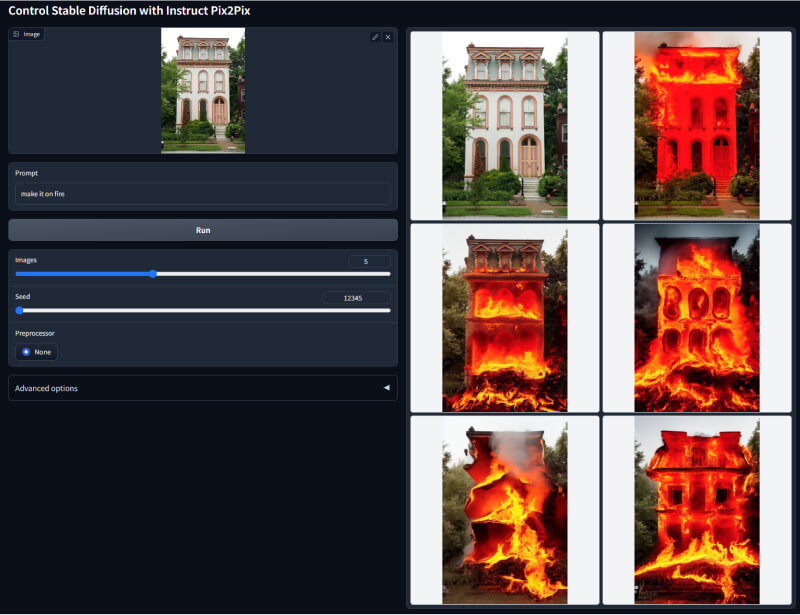
该模型可以根据用户输入的文本描述直接编辑图像,如输入“让这栋房子着火”,模型就可以着火处理这栋房子。它需要用户具有一定的创意与想象力,可以实现直接控制生成意想不到的效果。
7. Tile模型
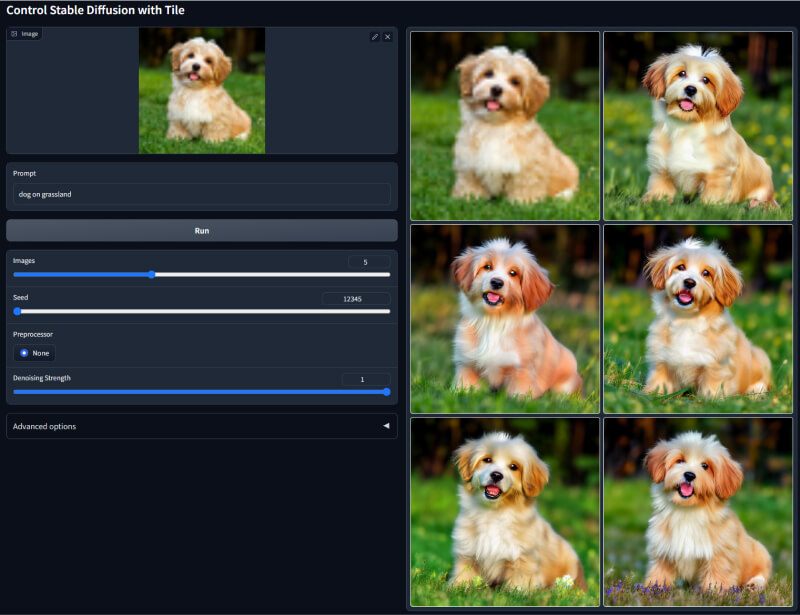
该模型将图像分割成多个小块,对每个小块单独进行处理,然后再拼接还原成完整图像。它常用于放大图像时增加细节,或者用于图像修复等场景。分割成小块进行处理可以更好地保留图像细节,避免直接放大导致的线条失真和噪点。
8. Inpaint修补模型
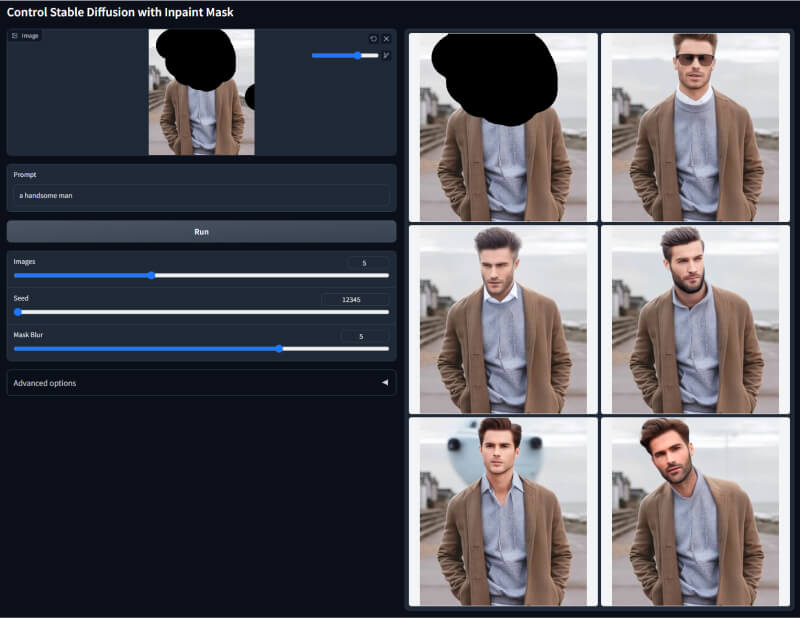
该模型可以对图像进行局部的重绘与修饰,用于小范围的创意设计,如增加色彩、细节等。它可以对指定区域进行处理,保留图像其他部分不变。
下面几款模型模型主要是线性检测模型,分别精细作用于不同的领域:
9. Canny边缘检测模型

该模型使用Canny算法检测图像中的边缘线条,通过边缘判断图像主体的范围和轮廓。它可以滤除图像细节,仅保留主要边缘,再根据边缘进行填色。
10. Lineart线性检测模型
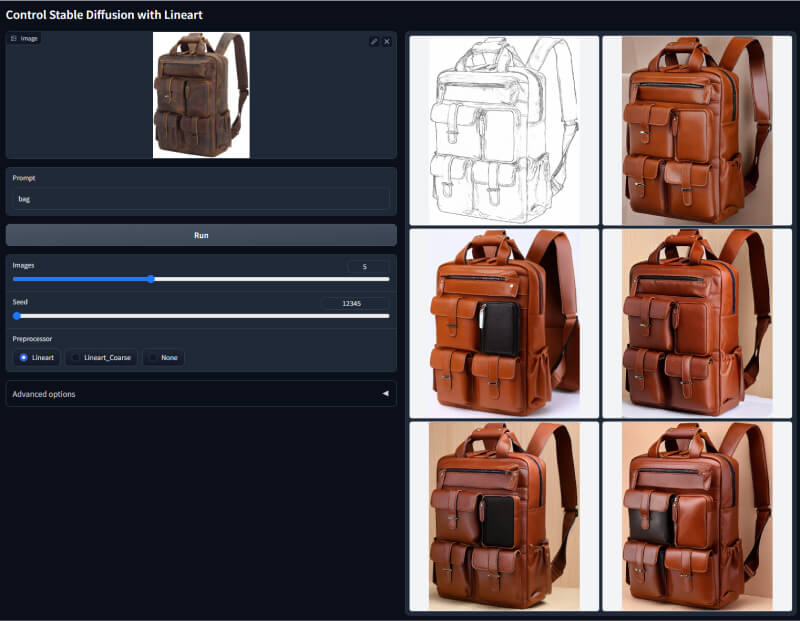
相较于 Canny,Lineart 提取的线稿更加精细,细节更加丰富,适用于产品设计等方面。
11. Anime Lineart动漫线性检测模型
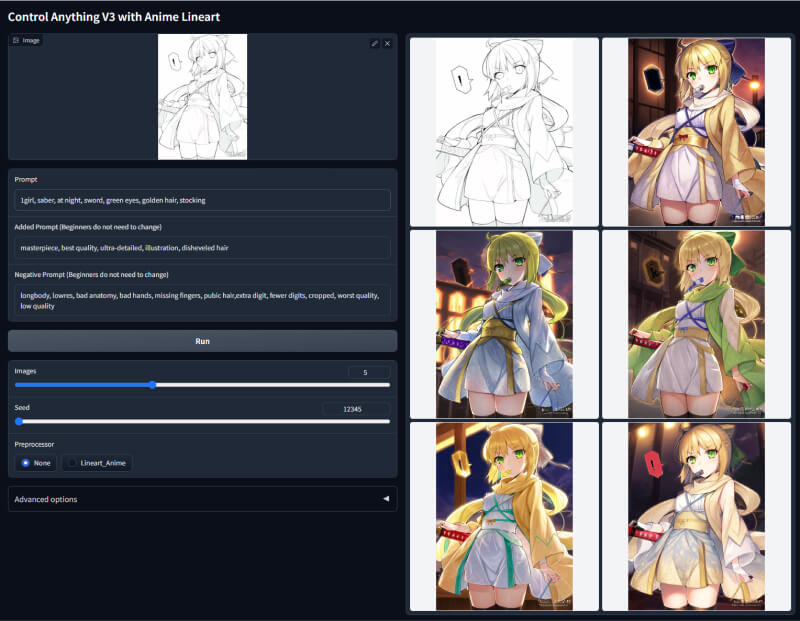
该模型是Lineart线性检测模型的升级版,专门用于动漫线稿的上色,效果更加自然流畅。
12. Softedge软线性检测模型
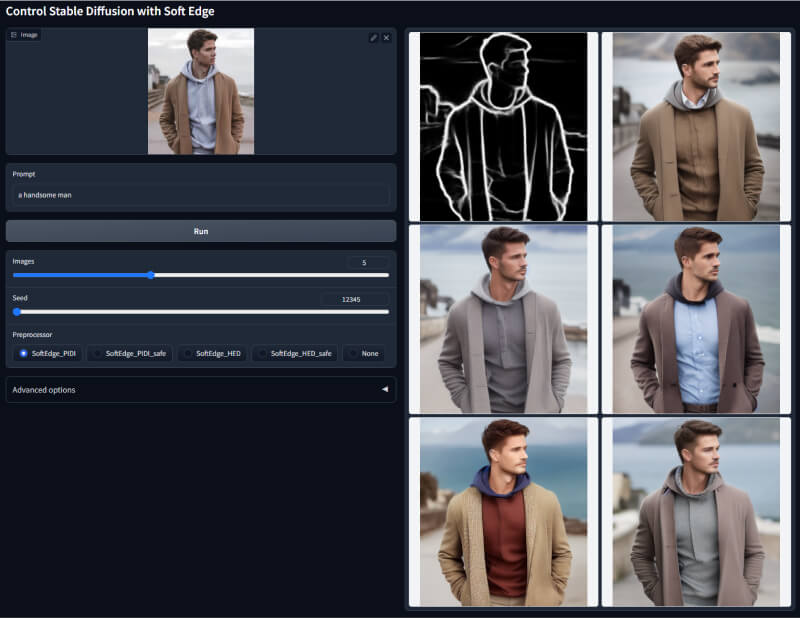
该模型也是一款边缘检测模型,但其生成的线条变得更加柔和,边缘处理更加自然,避免生硬的效果。
13. MLSD模型
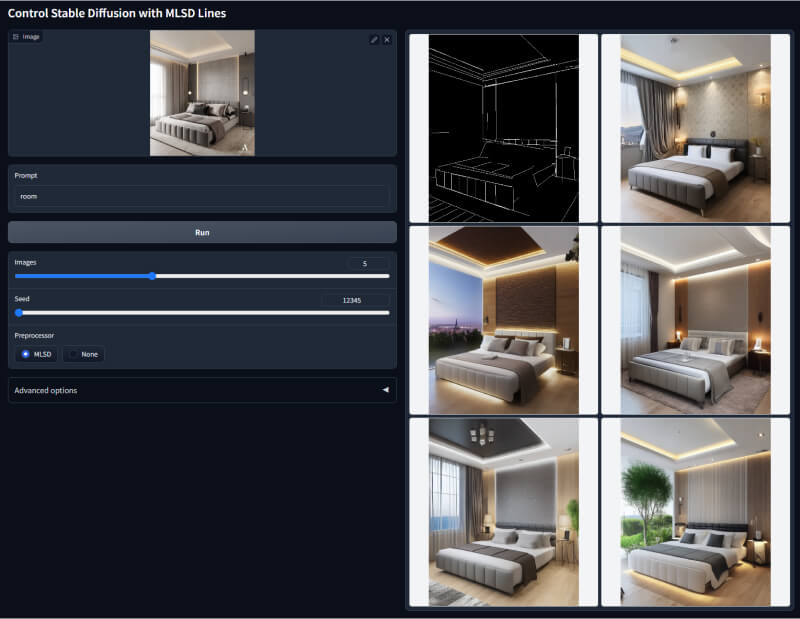
该模型也是一款线性检测模型,善于直线线段的提取,比如建筑的线条结构和几何形状,比较适合用于建筑/室内设计风格模型来生成图像。
14. Scribble涂鸦模型
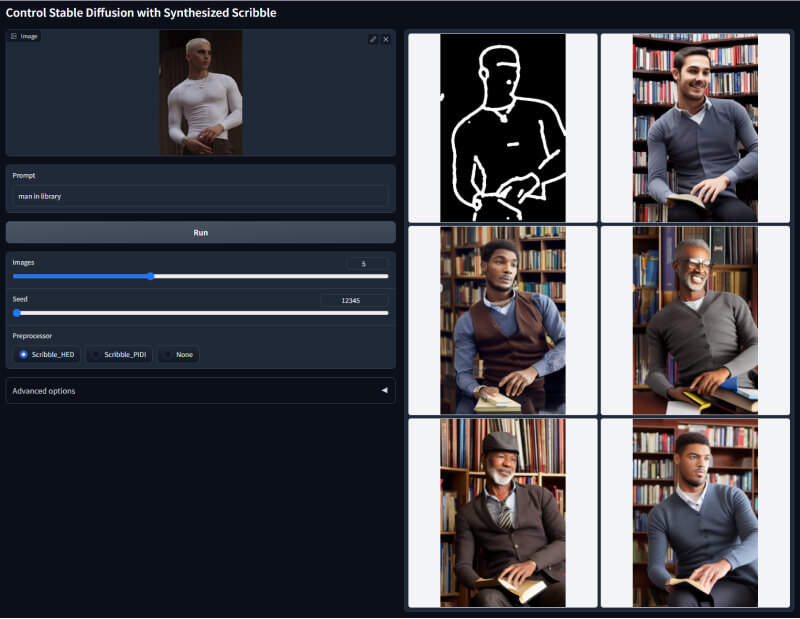
该模型可以提取用户用户输入手绘的线条、线段等涂鸦,然后可以基于这些输入生成相关的图像输出。
版权声明:此文章来自标记狮社区,转载请附上原文出处链接。
原文链接:https://ui.marklion.cn/article/7e7/06/article-2ad6830869c1feee.shtml